Análisis de texto con R: jugando un poco con tidytext
Hace unos meses me leí el libro de Text Mining with R de Julia Silge y David Robinson. En él, los autores introducen el término tidy text format para referirse a la adaptación de los principios del tidyverse a todo lo referido al análisis de texto. Si te interesa el tema, una lectura muy recomendable.
Una de las cosas que me interesaba comprobar es cuán fácil es replicar algunos análisis del libro con datos reales (los del libro también lo son, pero evidentemente los ejemplos son agradecidos) y también con texto en español. Sin darle muchas vueltas, he tomado unos datos de Twitter relacionados con mi equipo de fútbol.
En primer lugar, cargo las librerías:
pkgs <- c("rtweet",
"stringr",
"tidytext",
"quanteda",
"wordcloud",
"readr",
"purrr",
"dplyr",
"ggplot2")
invisible(lapply(pkgs, require, character.only = TRUE))Ahora vamos a generar el token para poder acceder a Twitter Developer. No voy a extenderme aquí, el paquete rtweet tiene excelentes vignettes donde explican cómo hacerlo.
# creacion del token
token <- create_token(
app = Sys.getenv("app_name"),
consumer_key = Sys.getenv('api_key') ,
consumer_secret = Sys.getenv('api_secret_key') ,
access_token = Sys.getenv('access_token') ,
access_secret = Sys.getenv('access_token_secret')
)A continuación he tomado la información de todos aquellos tuits que contienen referencias a @UDLP_Oficial, @udlaspalmasNET y “UD Las Palmas”, así como todos los tuits publicados por el principal portal del aficionado, @udlaspalmasNET. Excluyo de aquí los publicados por el canal oficial del club por no introducir un sesgo evidente 😄.
rt <- map_df(c("@UDLP_Oficial", "@udlaspalmasNET", "UD Las Palmas", "#UDLP"),
function(x) search_tweets(x, n = 1e10, include_rts = FALSE))
rt_net <- get_timeline("udlaspalmasNET", n = 10000) %>%
dplyr::filter(created_at >= min(rt$created_at) & created_at <= max(rt$created_at))
# se unen los tuits provenientes de los keywords y los del timeline de @udlaspalmasNET
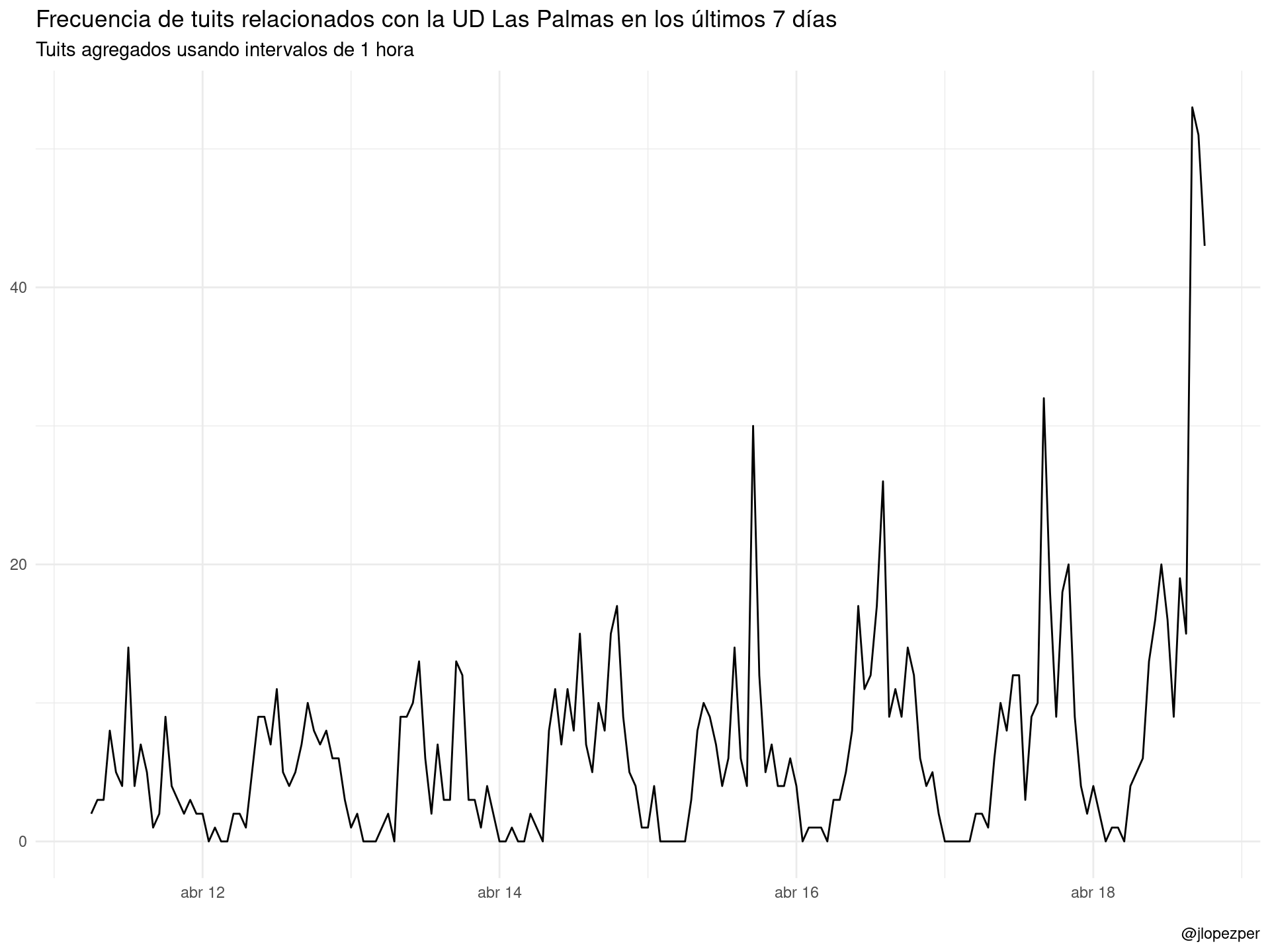
rt_all <- bind_rows(rt, rt_net)Esta es la pinta que tiene la frecuencia de tuits relacionados con el equipo. Hay dos picos evidentes durante el 17 de noviembre, días de partido tanto del filial (por la mañana) como del primer equipo, esa misma tarde.
ts_plot(rt_all, "1 hours") +
ggplot2::theme_minimal() +
ggplot2::labs(
x = NULL, y = NULL,
title = "Frecuencia de tuits relacionados con la UD Las Palmas en los últimos 7 días",
subtitle = "Tuits agregados usando intervalos de 1 hora",
caption = "\n@jlopezper"
)
De acuerdo, ahora vamos limpiar un poco los tuits y dejarlos en formato tidy (one-token-per-row). Lo hacemos en tres pasos:
- Limpiamos todas las URL de enlaces que aparezcan en los tuits.
- Seleccionamos los campos de interés.
- Con la función
unnest_tokens()dividimos la columna de texto en tokens (unidad de texto, palabras). - Por último, eliminamos los stopwords usando la función
tm::stopwords().
tidy_rt <-
rt_all %>%
mutate(text = str_replace_all(text, '(http|https)[^([:blank:]|\\"|<|&|#\n\r)]+', "")) %>%
select(created_at, screen_name, text) %>%
unnest_tokens(word, text) %>%
anti_join(tibble(word = tm::stopwords("es")))
# este seria el resultado
sample_n(tidy_rt, 10)## # A tibble: 10 x 3
## created_at screen_name word
## <dttm> <chr> <chr>
## 1 2020-04-16 13:02:32 ramirez_perera erauncrass
## 2 2020-04-17 09:46:10 lucasbravode mejores
## 3 2020-04-12 10:54:44 Jose1073r1 udlp_oficial
## 4 2020-04-12 15:10:26 RuymanAlmeidaP todogolesradio
## 5 2020-04-12 15:55:16 marriaga1974 hace
## 6 2020-04-13 08:03:27 PERICOSAFE memoriaudlp
## 7 2020-04-17 16:07:19 TDCdeportes entrega
## 8 2020-04-11 06:33:56 kaskai19 sabian
## 9 2020-04-17 20:55:15 BattaAlex acuerdo
## 10 2020-04-11 07:54:20 icocoru eofutbolUna pregunta natural: ¿cuáles son las palabras más frecuentes?
tidy_rt %>%
count(word, sort = TRUE) %>%
mutate(word = reorder(word, n)) %>%
dplyr::filter(n > 100 & word != "udlp_oficial") %>%
ggplot(aes(word, n)) +
ggplot2::labs(
y = "# veces que aparece",
x = "Palabra",
title = "Palabras más repetidas (> 100 veces)",
caption = "\n@jlopezper"
) +
geom_col() +
coord_flip() +
theme_minimal()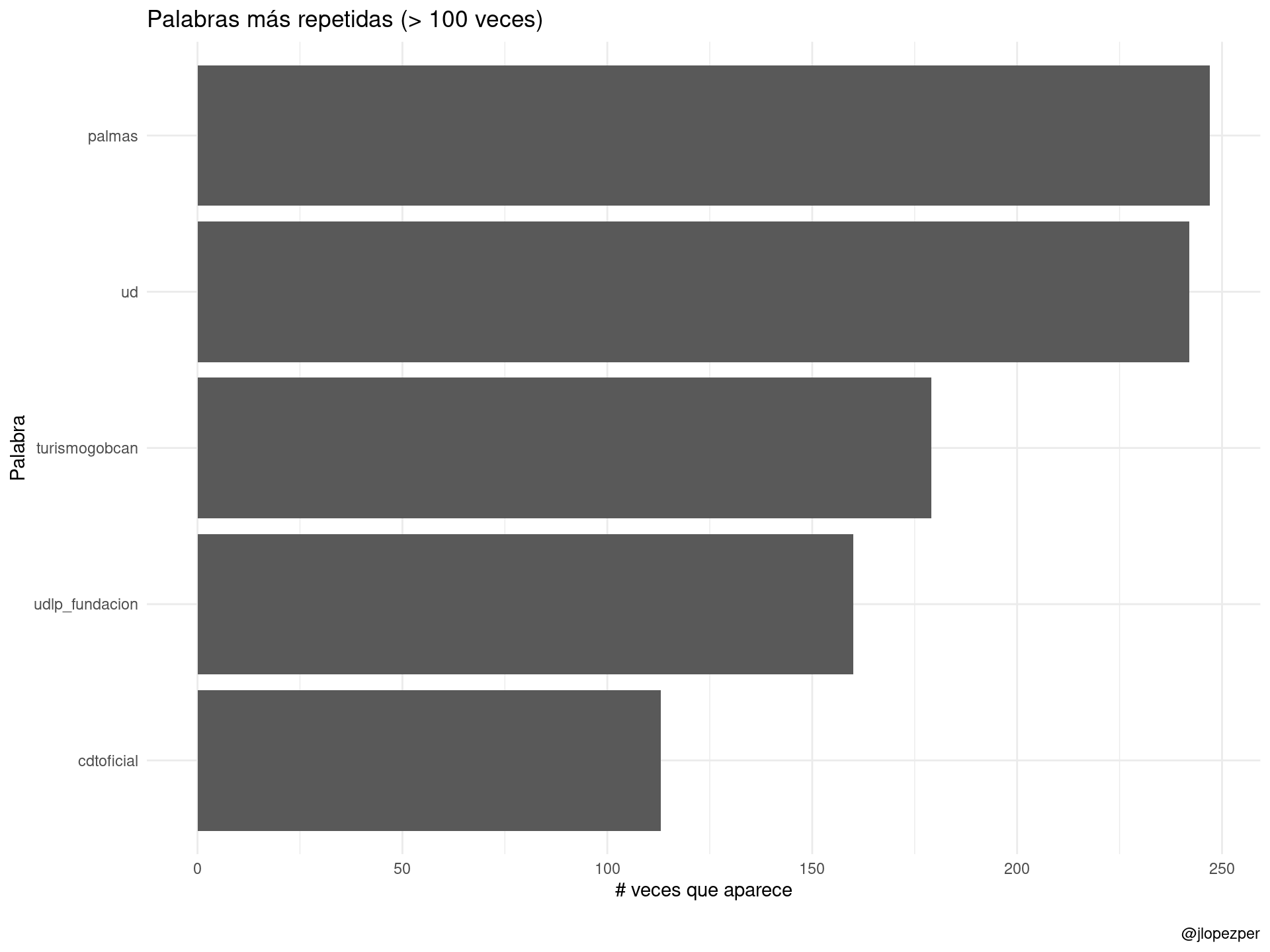
También se puede ver con la clásica nube de palabras en donde se ve alguna cosa curiosa:
- Hay dos enteros (1, 2), que hacen referencia al resultado del último partido (2-1).
- También se ve la relevancia del hashtag #ramirezveteya, que hace referencia a la demanda de la salida del presidente por parte de un sector de la afición (una búsqueda rápida en Google igual ilustra por qué 🙄).
- Se hace referencia al CD Castellón, que será el próximo rival en la Copa del Rey así como al Mirandés, último rival al que se enfrentó.
- Aparece el nombre de Pedri, uno de los jugadores más destacados esta temporada.
tidy_rt %>%
count(word, sort = TRUE) %>%
dplyr::filter(n > 30 & word != "udlp_oficial") %>%
with(wordcloud::wordcloud(words = word,
freq = n,
max.words = 300,
random.order = FALSE,
rot.per = 0.3,
colors = brewer.pal(8,"Dark2")))## Warning in wordcloud::wordcloud(words = word, freq = n, max.words = 300, :
## udlp_fundacion could not be fit on page. It will not be plotted.## Warning in wordcloud::wordcloud(words = word, freq = n, max.words = 300, :
## wakasobobby could not be fit on page. It will not be plotted.## Warning in wordcloud::wordcloud(words = word, freq = n, max.words = 300, :
## esports_udlp could not be fit on page. It will not be plotted.## Warning in wordcloud::wordcloud(words = word, freq = n, max.words = 300, :
## pericosafe could not be fit on page. It will not be plotted.## Warning in wordcloud::wordcloud(words = word, freq = n, max.words = 300, :
## aarondogoro could not be fit on page. It will not be plotted.## Warning in wordcloud::wordcloud(words = word, freq = n, max.words = 300, :
## jugadores could not be fit on page. It will not be plotted.## Warning in wordcloud::wordcloud(words = word, freq = n, max.words = 300, :
## tanadp_24 could not be fit on page. It will not be plotted.## Warning in wordcloud::wordcloud(words = word, freq = n, max.words = 300, :
## ultranaciente could not be fit on page. It will not be plotted.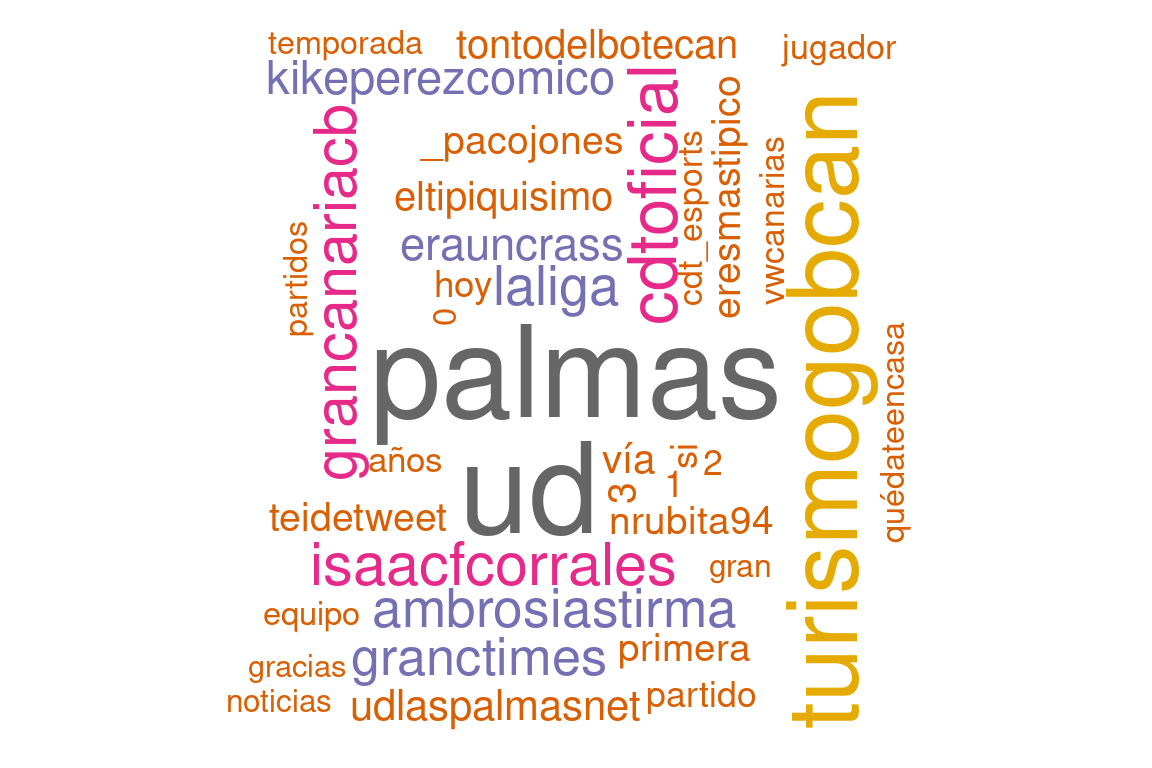
Ahora vamos con algo de análisis de sentimiento. Para ello, tomamos el siguiente diccionario de sentimientos. En honor a la verdad, no está muy pulido y he visto errores que he corregido sobre la marcha, pero vale para una primera intentona.
positive_words <-
read_csv(here::here("resources", "data", "positive_words_es.txt"), col_names = "word") %>%
mutate(sentiment = "positive")
negative_words <-
read_csv(here::here("resources", "data", "negative_words_es.txt"), col_names = "word") %>%
mutate(sentiment = "negative")
sentiment_words <- bind_rows(positive_words, negative_words)Construimos ahora el dataset agregando la información de sentimiento y hacemos el conteo agrupando por token-sentimiento.
tidy_rt_sent <-
tidy_rt %>%
inner_join(sentiment_words) %>%
count(word, sentiment, sort = TRUE) %>%
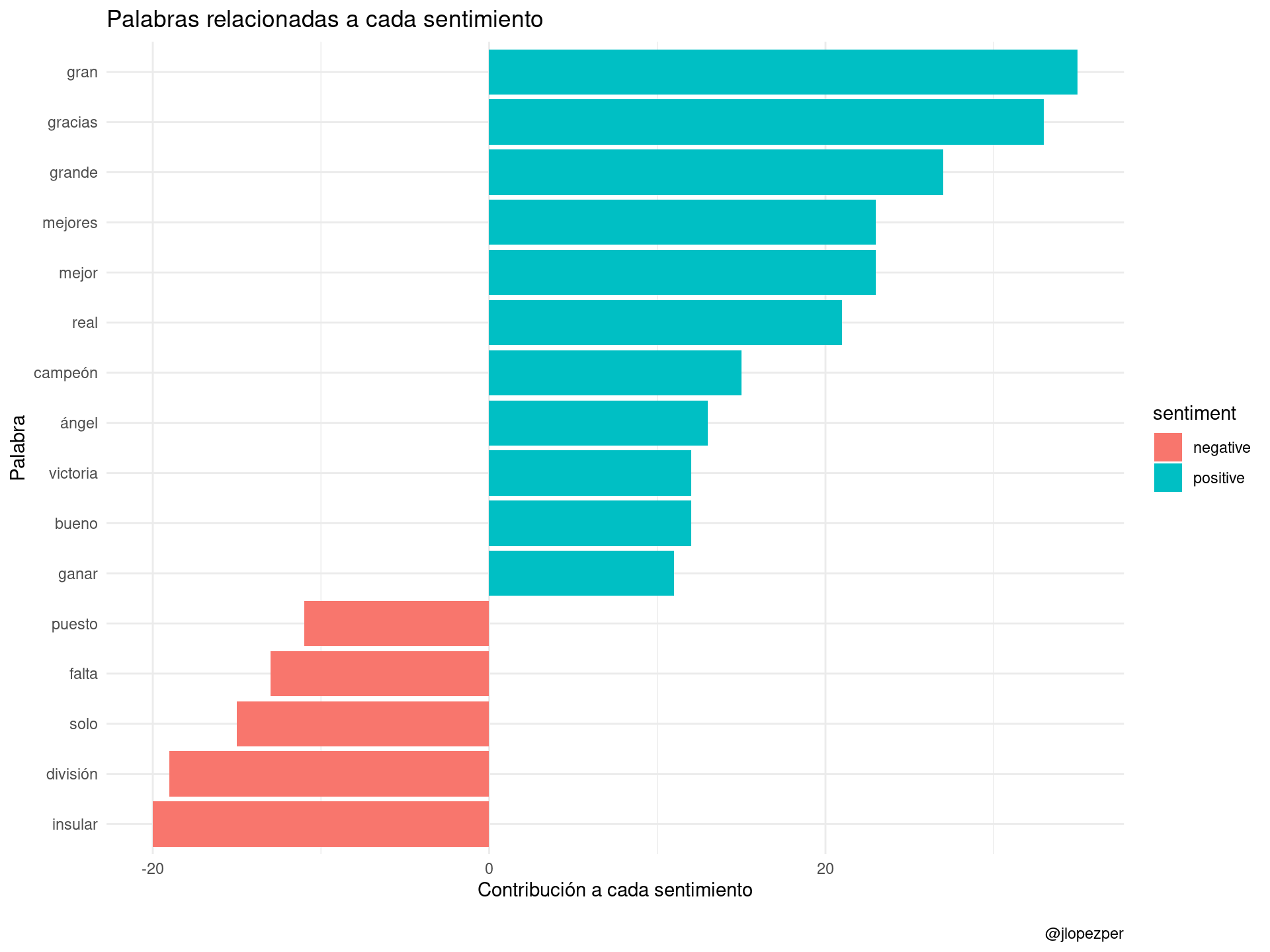
ungroup()Ahora podemos hacer un gráfico de aquellas palabras que más contribuyen a los sentimientos positivo y negativo, siempre limitándonos al diccionario anterior. Aquí se pueden ver algunos errores en la asignación de determinados sentimientos a algunas palabras que, desde luego, no se perciben como tal.
tidy_rt_sent %>%
filter(n > 10) %>%
mutate(n = ifelse(sentiment == "negative", -n, n)) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentiment)) +
geom_col() +
coord_flip() +
labs(y = "Contribución a cada sentimiento",
x = "Palabra",
title = "Palabras relacionadas a cada sentimiento",
caption = "\n@jlopezper") +
theme_minimal()